El Software de reconocimiento óptico de caracteres de Google ya es compatible con todos los idiomas del sur de Asia



El proceso paso a paso para utilizar el software de reconocimiento óptico de caracteres de Google y que es compatible con casi todos los idiomas principales del sur de Asia. Imagen de Subhashish Panigrahi, con licencia gratuita CC-by-SA 4.0.
El software de Reconocimiento Óptico de Caracteres (OCR, por sus siglas en inglés) creado por Google ya trabaja con más de 248 idiomas del mundo, incluidos los principales idiomas surasiáticos, además de ser fácil de usar y tener un 90 por ciento de precisión en la mayoría de los idiomas.
El software OCR ha sido muy benéfico para el estudio del idioma ya que ayuda a extraer el texto de imágenes de prácticamente cualquier texto impreso, e incluso en algunas ocasiones, de texto escrito a mano, lo que abre la puerta a textos antiguos, manuscritos y más.
Ketan Pratap de NDTV Gadgets escribió:
Users can start using the OCR capabilities in Drive by uploading scanned document in PDF or image form after which they can right-click on the document in Drive to open with Google Docs. After choosing the option, a document with the original image alongside extracted text opens, which can be edited. Google notes that users will not be required to specify the language of the document as the OCR in Drive will automatically determine it. The OCR capability in Google Drive is also available in Drive for Android.
Los usuarios pueden empezar a utilizar las propiedades del OCR en Drive al subir el documento digitalizado en formato PDF o en imagen y posteriormente dar clic en el botón derecho del ratón sobre el documento en Drive para abrirlo con Documentos de Google. Después de elegir la opción, un documento se abre junto con el texto extraído y la imagen original, la cual se puede editar. Google aclara que los usuarios no tendrán que especificar el idioma del documento ya que el OCR de Drive lo determinará de forma automática. La función OCR de Google Drive también se encuentra disponible en Drive para Android.
Varios usuarios en Twitter también recibieron favorablemente esta nueva función de Google:
Optical Character Recognition #OCR in Google Drive recongnizes many indic languages including #Kannada give it a try http://t.co/99UkCJQ6gb
— Omshivaprakash (@omshivaprakash) August 28, 2015
El reconocimiento óptico de caracteres OCR en Google Drive reconoce varios idiomas índicos, incluido el Kannada, pruébalo.
@shylobisnett if you have access to a scanner, you can do OCR through google drive. works a bit faster.
— Whet Moser (@whet) August 27, 2015
Una de las partes más fastidiosas de manejar un grupo comunitario es escribir en correos electrónicos recogidos en papel.
@shylobisnett si tienes acceso a un digitalizador, puedes hacer un OCR a través de google drive. trabaja un poco más rápido.
Wow. Searching Google Drive for a keyword also returns results for images containing that keyword in the image. Didn't realise it did OCR.
— Mark Osborne (@mosborne01) August 25, 2015
Guau. Al buscar una palabra clave en Google Drive también arroja resultados de imágenes que contienen esa palabra clave en la imagen. No me había dado cuenta que hacía OCR.
Normalmente el software de OCR tenía dificultad al leer el texto de documentos antiguos o páginas con manchas o marcas de tinta, ya que arrojaba garabatos en vez de texto legible.
La página de soporte técnico de Google referente a este proyecto comparte información adicional sobre el formateo de caracteres, como la habilidad de mantener las fuentes negrita y cursiva en el texto de salida:
When processing your document, we attempt to preserve basic text formatting such as bold and italic text, font size and type, and line breaks. However, detecting these elements is difficult and we may not always succeed. Other text formatting and structuring elements such as bulleted and numbered lists, tables, text columns, and footnotes or endnotes are likely to get lost.
Al procesar tu documento tratamos de conservar el formato básico del texto, como las negritas y cursivas, el tamaño y tipo de la fuente y los saltos de línea. Sin embargo, la detección de estos elementos es complicada y es posible que no siempre podamos lograrlo. Algunos otros elementos de formato y estructura, como las listas numeradas y viñetas, tablas, texto en columnas y pies de página o acotaciones, seguramente se perderán.
Para algunos idiomas como el malayalam y el tamil, el OCR trabaja con una precisión del 100 por ciento e incluye soporte para algunas características de formato como el recorte automático, separación de texto eliminando imágenes y omisión del color de fondo; así lo explica un usuario en idioma tamil y el usuario de Facebook Wikimedian Ravishankar Ayyakkannu:
[…] Google Tamil OCR works with 100% accuracy ! Keep testing with various samples and comment here. Performance has been the same for many other Indic languages too. […] Auto crops, discards images and colored background. Recognizes different layouts. I could find only 1 mistake in whole page. Testing latest Vikatan – https://docs.google.com/…/1OXre4…/edit.. […]
[…] ¡El OCR Tamil de Google trabaja con un 100% de precisión! Sigan probando con otros formatos y dejen su comentario aquí. El desempeño ha sido el mismo para otros idiomas índicos. […] Recorte automático, eliminación de imágenes y establecimiento de color de fondo. Reconoce diferentes diseños. Solamente encontré un error en toda la página. Estoy probando el último, idioma Vikatan. https://docs.google.com/document/d/1OXre4-phQOayE0wyGTttQq-eD3Djt_alsuhkmS8BeRI/edit?usp=sharing
(Usuarios de idiomas bengalí, malayalam, kannada, oriya, tamil y télugu han dejado sus comentarios en la misma publicación con su respectiva retroalimentación después de haber probado el software actualizado OCR. Para algunas escrituras como el gurmukhi (se solía escribir panyabí), resulta que el resultado del OCR es muy pobre ya que solo arrojó garabatos cuando se probó con una imagen de Wikipedia en panyabí).
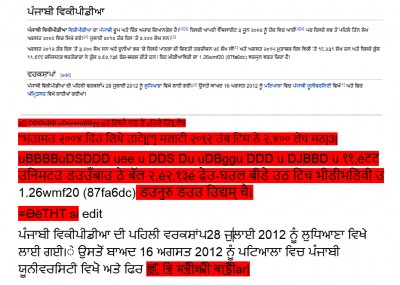
Problemas con texto en gurmukhi después de la lectura del OCR de Google. Imagen de Wikipedia en Panyabí.
Este es un gran salto para los idiomas que poseen muchos textos antiguos que no han sido digitalizados; textos antiguos y valiosos en varios idiomas que ya podrían digitalizarse y compartirse en la Internet utilizando plataformas como Wikisource y que podrían conservarse y ponerse a disposición para compartir conocimiento.
El OCR de Google utiliza parcialmente Tesseract, un motor OCR libre. Se desarrolló como un proyecto en conjunto entre 1995 y 2006 (después quedó a cargo de Google), se considera a Tesseract como uno de los motores OCR más precisos del mundo y trabaja con más de 60 idiomas. El código fuente se aloja en https://github.com/tesseract-ocr. Vean este enlace de resultados del OCR en distintos textos surasiáticos.

Este articulo es de Rising Voices, un proyecto de Global Voices que ayuda a difundir los medios ciudadanos en lugares que normalmente no tienen acceso a ellos. · Todos los articulos





